Adding coding rules
There are three ways to add coding rules to SonarQube:
- Writing a SonarQube plugin in Java that uses SonarQube APIs to add new rules
- Adding XPath rules directly through the SonarQube web interface
- Importing generic issue reports generated by an independently run tool
The Java API will be more fully-featured than what's available for XPath, and is generally preferable. However, this comes with the overhead of maintaining a SonarQube plugin (including keeping it up-to-date as APIs change, upgrading the plugin after releasing a new version).
Importing generic issue reports is a good solution when there's a very specific need for a subset of projects on your SonarQube instance. They are the most flexible option but lack some features (such as being able to control their execution by inclusion in a quality profile).
Before implementing a new coding rule, you should consider whether it is specific to your own context or might benefit others. If it might benefit others, you can propose it on the community forum. If there is a shared interest, then it might be implemented for you directly in the related language plugin. It means less maintenance for you and benefit to others.
Custom rule support by language
| XPath 1.0 | Java | Generic Issue Reports | Other | |
| ABAP | - | - |  | |
| Apex | - | - | | |
| Azure Resource Manager | - | - | | |
| C# | - | - | | Importing Issues from Third-Party Roslyn Analyzers (C#, VB.NET) |
| C / C++ / Objective-C | - | - | | |
| CloudFormation | - | - | | |
| COBOL | - | | | |
| CSS | - | - | | |
| Docker | - | - | | |
| Flex | | - | | |
| Go | - | - | | |
| HTML | - | - | | |
| Java | - | | | |
| JavaScript / Typescript | - | - | | |
| Kotlin | - | - | | |
| Kubernetes | - | - | | |
| PHP | - | | | |
| PL/SQL | | - | | |
| PL/I | | - | | |
| Python | - | | | |
| RPG | - | | | |
| Ruby | - | - | | |
| Scala | - | - | | |
| Secrets | - | - | | |
| Swift | - | - | | |
| Terraform | - | - | | |
| T-SQL | - | - | | |
| VB.NET | - | - | | Importing Issues from Third-Party Roslyn Analyzers (C#, VB.NET) |
| VB6 | - | - | | |
| XML | | - | |
Adding coding rules using Java
Writing coding rules in Java is a six-step process:
- Create a SonarQube plugin.
- Put a dependency on the API of the language plugin for which you are writing coding rules.
- Create as many custom rules as required.
- Generate the SonarQube plugin (jar file).
- Place this jar file in the
<sonarqubeHome>/extensions/pluginsdirectory. - Restart SonarQube server.
See the following pages to see samples and details about how to create coding rules
Note: Custom rules written in Java will run in SonarLint if SonarLint compatibility is properly notated in the custom plugin manifest, see this example for the syntax.
Adding coding rules using XPATH
SonarQube provides a quick and easy way to add new coding rules directly via the web interface for certain languages using XPath 1.0 expressions. For XML, which is already immediately accessible to XPath, you can simply write your rules and check them using any of the freely available tools for examining XPath on XML. If you're writing rules for XML, skip down to the Adding your rule to the server section once you've got your rules written.
For other languages how to access a variable, for example, in XPath is less obvious, so we've provided tools.
Writing an XPath rule using SSLR toolkit
The rules must be written in XPath (version 1.0) to navigate the language's abstract syntax tree (AST). For most languages, an SSLR Toolkit is provided to help you navigate the AST. You need to download the sslr-{language}-toolkit-{version}.jar file corresponding to the version of your language plugin you have on your SonarQube instance.
Each language's SSLR Toolkit is a standalone application that displays the AST for a piece of code source that you feed into it, allowing you to read the node names and attributes from your code sample and write your XPath expression. Knowing the XPath language is the only prerequisite, and there are a lot of tutorials on XPath online.
The latest version of SSLR Toolkit can be downloaded from the following locations:
For an SSLR preview, consider the following source code sample:
function HelloWorld(hour) {
if (hour) {
this.hour = hour;
} else {
var date = new Date();
this.hour = date.getHours();
}
this.displayGreeting = function() {
if (this.hour >= 22 || this.hour <= 5)
document.write("Good night, World!");
else
document.write("Hello, World!");
}
}While parsing source code, SonarQube builds an abstract syntax tree (AST) for it, and the SSLR toolkit provided for each language will show you SonarQube's AST for a given piece of code. Here's the AST for our sample:

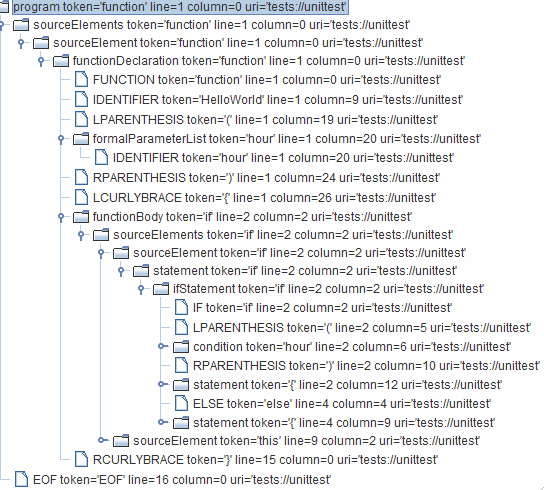
The XPath language provides a way to write coding rules by navigating this AST, and the SSLR toolkit for the language will give you the ability to test your new rules against your sample code.
Adding your Rule to the Server
Once your new rule is written, you can add it to SonarQube:
- Log in as a quality profile administrator.
- Go to the Rules page.
- Select the language for which you want to create the XPath rule.
- Tick the Template criterion and select Show Templates Only.
- Look for the XPath rule template.
- Click on it to select it, then use the interface controls to create a new instance.
- Fill in the form that pops up.
- Once you've created your rule, you'll need to add it to a quality profile and run an analysis to see it in action.
Coding rule guidelines
These are the guidelines that SonarSource uses internally to specify new rules. Rules in community plugins are not required to adhere to these guidelines. They are provided here only in case they are useful.
Note that fields "title", "description" and "message" have a different format when the rule type is "hotspot".
Guidelines applicable to all rules
Code examples
Do not give examples that make references to real companies or organizations:
$fp = file_get_contents("https://www.real-company.com"); Should be replaced by a neutral website:
$fp = file_get_contents("https//www.example.com");
// or even better:
$fp = file_get_contents("https://localhost");See/References
When a reference is made to the specification of a standard, e.g. MISRA, the following steps must also be taken:
- add any related tags such as security, bug, etc.
- add the relevant standard-related tag/label such as cwe, misra, etc. (If you forget, the overnight automation will remember for you.)
- update the appropriate field on the References tab with the cited id. (If you forget, the overnight automation will remember for you.)
If needed, references to other rules should be listed under a "see also" heading. If a "see" heading exists in the rule, then the "see also" title should be at the h3 level. Otherwise, use an h2 for it.
Other rules should be linked to only if they are related or contradictory (such as a pair of rules about where { should go).
Why list references to other rules under "see also" instead of "see"? The "see" section is used to support the current rule, and one rule cannot be used as justification for another rule.
Rule Type
Issue types (bug, vulnerability, and code smell) are deprecated. Issues are now tied to Clean Code attributes and software qualities impacted. See Clean Code for more details.
Now that you've fleshed out the description, you should have a fairly clear idea of what type of rule this is, but to be explicit:
Bug: Something that's wrong or potentially wrong.
Code Smell: Something that will confuse a maintainer or cause them to stumble in their reading of the code.
Vulnerability: Something that's wrong which impacts the application's security and therefore needs a fix.
Hotspot: An optional protection is missing and the developer needs to do a review before deciding whether to apply a fix.
Sometimes the line between bug and code smell is fuzzy. When in doubt, ask yourself: "Is code that breaks this rule doing what the programmer probably intended?" If the answer is "probably not" then it's a bug. Everything else is a code smell.
The main differences between vulnerabilities and hotspots are explained on the Security hotspots page. During the specification of a rule, the following guidelines might also help:
- The difficulty of exploiting a weakness should not be a criterion for specifying a hotspot or a vulnerability.
- Vulnerabilities and hotspots should not overlap but can be related to the same subject. For example, with the hotspot RSPEC-2077, formatted SQL queries are highlighted and we recommend the use of prepare statements as additional protection to prevent SQL-injection vulnerabilities (RSPEC-3649).
Default severities
When assessing the default severity of a rule, the first thing to do is ask yourself "what's the worst thing that could happen?" In answering, you should factor in Murphy's Law without predicting Armageddon.
Once you have your answer, it's time to assess whether the impact and likelihood of the worst thing are high or low. To do that, ask yourself these specific questions:
Vulnerability
- Impact: Could the exploitation of the vulnerability result in significant damage to your assets or your users? (Yes = High)
- Likelihood: What is the probability a hacker will be able to exploit it? what is the time to fix the issue?
Bug
- Impact: Could the bug cause the application to crash or corrupt stored data? (Languages where an error can cause program termination: COBOL, Python, PL/SQL, RPG.)
- Likelihood: What is the probability the worst will happen?
Code Smell
- Impact: Could the Code Smell lead a maintainer to introduce a bug?
- Likelihood: What is the probability the worst will happen?
Once you have your impact and likelihood assessments, the rest is easy:
| impact | likelihood | |
| Blocker | Y | Y |
| Critical | Y | N |
| Major | N | Y |
| Minor | N | N |
Tags
Rules can have 0-n tags, although most rules should have at least one. Many of the common-across-languages tags are described in the rules docs.
Evaluation of the remediation cost
For most rules, the SQALE remediation cost is constant per issue. The goal of this section is to help define the value of this constant and to unify the way those estimations are done to prevent having some big discrepancies among language plugins.
First, classify the effort to do the remediation:
- TRIVIAL: No need to understand the logic and no potential impact. Examples:
- Remove unused imports.
- Replace tabulations by spaces.
- Remove call to
System.out.println()used for debugging purposes.
- EASY: : No need to understand the logic but potential impacts. Examples:
- Rename a method.
- Rename a parameter.
- Remove unused private method.
- MEDIUM: Understanding the logic of a piece of code is required before doing a little and easy refactoring (1 or 2 lines of code), but understanding the big picture is not required. Examples:
- CURSORs should not be declared inside a loop.
- EXAMINE statement should not be used.
IFshould be closed withEND-IF.
- MAJOR: Understanding the logic of a piece of code is required and it's up to the developer to define the remediation action. Examples:
- Too many nested IF statements.
- Methods should not have too many parameters.
- UNION should not be used in SQL SELECT statements.
- Public Java method should have a javadoc.
- Avoid using deprecated methods.
- HIGH: The remediation action might lead to a local impact on the design of the application. Examples:
- Classes should not have too many responsibilities.
- Cobol programs should not have too many lines of code.
- Architectural constraint.
- COMPLEX: The remediation action might lead to an impact on the overall design of the application. Examples:
- Avoid cycles between packages.
Then use the following table to get the remediation cost according to the required remediation effort and to the language:
| Trivial | Easy | Medium | Major | High | Complex | |
| ABAP, COBOL, ... | 10min | 20min | 30min | 1h | 3h | 1d |
| Other languages | 5min | 10min | 20min | 1h | 3h | 1d |
For rules using either the "linear" or "linear with offset" remediation functions, the "Effort To Fix" field must be fed on each issue and this field is used to compute the remediation cost.
Issue location(s) and highlighting
For any given rule, highlighting behavior should be consistent across languages within the bounds of what's relevant for each language.
When possible, each issue should be raised on the line of code that needs correction, with highlighting limited to the portion of the line to be corrected. For example:
- An issue for a misnamed method should be raised on the line with the method name, and the method name itself should be highlighted.
When correcting an issue requires action across multiple lines, the issue should be raised on the lowest block that encloses all relevant lines. For example an issue for:
- Method complexity should be raised on the method signature.
- Method count in a class should be raised on the class declaration.
When an issue could be made clearer by highlighting multiple code segments, such as a method complexity issue, additional issue locations may be highlighted, and additional messages may optionally be logged for those locations. In general, these guidelines should be followed for secondary issue locations:
- Highlight the minimum code to show the line's contribution to the issue.
- Avoid using an additional message if the secondary location is likely to be on the same issue as the issue itself. For example, the rule "Parameters should be final" will raise an issue on the method name, and highlight each non-final parameter. Since all locations are likely to be on the same line, additional messages would only confuse the issue.
- Don't write a novel. The message for a secondary location is meant to be a hint to push the user in the right direction. Don't take over the interface with a narrative.
Guidelines when writing rules for issues
Titles
- The title of the rule should match the pattern "X should [ not ] Y" for most rules. Note that the "should [ not ]" pattern is too strong for Finding rules, which are about observations on the code. Finding titles should be neutral, such as "Track x".
- All other things being equal, the positive form is preferred. For example:
- "X should Y" is preferred to
- "X should not Z"
- Titles should be written in the plural form if at all possible. For example:
- Flibbers should gibbet is preferred to
- A Flibber should gibbet
- Any piece of code in the rule title should be double-quoted (and not single-quoted).
- There should be no category/tag prefixed to the rule title, such as "Accessibility - Image tags should have an alternate text attribute"
- Titles should be as concise as possible. Somewhere around 70 or 80 characters is an ideal maximum, although this is not always achievable.
Noncompliant title examples:
- A file should not have too many lines of code // Noncompliant; singular form used
- Avoid files with too many lines of code // Noncompliant; doesn't follow "x should [not] y" pattern
- Too many lines of code // Noncompliant
- Don't use "System.(out/err)" // Noncompliant
- Parameters in an overriding virtual function should either use the same default arguments as the function they override, or not specify any default arguments // Noncompliant; much too long
Compliant solutions:
- Files should not have too many lines of code
- "System.(out/err)" should not be used to log messages
- Overriding virtual functions should not change parameter defaults
Starting with the subject, such as "Files", will ensure that all rules applying to files will be grouped together.
Descriptions
Rule descriptions should contain the following sections in the listed order:
- Introduction: (optional) Short summary of the topic that is no longer than a few sentences to add clarity if the title is does not provide enough clarity of the issue.
- Why is this an issue: Explains why this rule and the concepts behind these types of issues.
- This section includes the following subsections
- What is the potential impact?: (optional) What are the risks associated with this rule including examples.
- How can I fix it?: Explain one or multiple ways to fix this issue.
- Noncompliant Code Example: Providing some examples of issues
- Ideally, the examples should depend upon the default values of any parameters the rule has, and these default values should be mentioned before the code block. This is for the benefit of users whose rule parameters are tuned to something other than the default values. E.G. With a parameter of:
:.log4j.* - The lines in these code samples where issues are expected should be marked with a "Noncompliant" comment
- "Compliant" comments may be used to help demonstrate the difference between what is and is not allowed by the rule
- It is acceptable to omit this section when demonstrating noncompliance would take too long, e.g. "Classes should not have too many lines of code"
- Ideally, the examples should depend upon the default values of any parameters the rule has, and these default values should be mentioned before the code block. This is for the benefit of users whose rule parameters are tuned to something other than the default values. E.G. With a parameter of:
- Compliant Solution: Demonstrating how to fix the previous issues. Good to have but not required for rules that detect bugs.
- There is no need to mark anything "Compliant" in the Compliant Solution; everything here is compliant by definition
- It is acceptable to omit this section when there are too many equally viable solutions.
- Noncompliant Code Example: Providing some examples of issues
- This section includes the following subsections
- How does it work?: (optional) Explain why this fixes the problem. There can be multiple ways of fixing the issue.
- Pitfalls: (optional) One or multiple pitfalls to take into account when working on fixing this issue.
- Going the extra mile: (optional) Even though the issue might be fixed, most of the time there can be way/s to further improve on this issue or to harden your project.
- Exceptions: (optional) Listing and explaining some specific use cases where no issues are logged even though some might be expected.
- More info: (optional) Listing references and/or links to external standards like MISRA, SEI, CERT, etc.
Code samples for COBOL should be in upper case.
When displayed in SonarQube, any code or keywords in the description should be enclosed in <code> tags. For descriptions written in JIRA, this means using double curly braces ({{ and }}) to enclose such text. They will be translated in the final output.
Messages
Issue messages should contain the remediation message for bug and quality rules. For potential-bug rules, it should make it explicit that a manual review is required. It should be in the imperative mood ("Do x"), and therefore start with a verb.
An issue message should always end with a period ('.') since it is an actual sentence unless it ends with a regular expression, in which case the regular expression should be preceded by a colon and should end the message.
Any piece of code in the rule message should be double-quoted (and not single-quoted). Moreover, if an issue is triggered because a number was above a threshold value, then both the number and the threshold value should be mentioned in the issue message.
Sample messages:
- Remove or refactor this useless "switch" statement. // Compliant
- This "switch" statement is useless and should be refactored or removed. // Noncompliant
- Every "switch" statement shall have at least one case clause. // Noncompliant
- Rename this variable to comply with the regular expression: [a-z]+ // Compliant
Sample Specification
Generic exceptions should not be thrown
Using generic exceptions such as Error, RuntimeException, Throwable, and Exception prevents calling methods from handling true, system-generated exceptions differently than application-generated errors.
Noncompliant Code Example
With the default regular expression [a-z][a-zA-Z0-9]+:
try { /* ... */ } catch (Exception e) { LOGGER.info("context"); } // Noncompliant; exception is lost
try { /* ... */ } catch (Exception e) { LOGGER.info(e); } // Noncompliant; context is required
try { /* ... */ } catch (Exception e) { LOGGER.info(e.getMessage()); } // Noncompliant; exception is lost (only message is preserved)
try {
/* ... */
} catch (Exception e) { // Noncompliant - exception is lost
throw new RuntimeException("context");
}Compliant Solution
try { /* ... */ } catch (Exception e) { LOGGER.info("context", e); }
try {
/* ... */
} catch (Exception e) {
throw new RuntimeException("context", e);
}Exceptions
Generic exceptions in the signatures of overriding methods are ignored.
@Override
public void myMethod() throws Exception {...}See
- MISRA C:2004, 4.5.2
- MITRE, CWE-580 - clone() Method Without super.clone()
See also
S4567 - Rule title here
Guidelines for Hotspot rules
See RSPEC-6502 for an example of a Hotspot rule.
Titles
- The title should start with a verb in the present participle form (-ing)
- The title should end with "is security-sensitive"
Noncompliant Title Examples:
- Avoid the creation of cookies without the "secure" flag
Compliant Solution:
- Creating cookies without the "secure" flag is security-sensitive
Descriptions
Rule descriptions should contain the following sections in the listed order:
- Rationale: (unlabeled) Explains why this rule makes sense.
- It starts with a copy of the title. The "is security sensitive" part can be replaced with "can lead to ..." when there is one risk and it is easy to describe in a short manner.
- Ask Yourself: A set of questions that the developer should ask herself/himself.
- Those questions should help the developer to decide whether or not a missing protection has to be implemented based on the context of the application. For example, if the highlighted missing protection (such as a secure cookie flag) helps protect a bit against MITM attacks, list all mandatory protections that, on the contrary, greatly lower this risk (such as encryption). At the end of the review, the developer should be sure that in its context the implementation of this protection improves the overall application's security.
- The hotspot-review should be done by developers by themselves without external help:
- It is not recommended to drive the review with data sensitivity (eg: "if this data/feature/component is sensitive there is a risk") because this concept is too generic and the use of the application (with or without sensitive data) may vary over time and cannot be controlled by developers.
- It is not recommended to highlight a widely-used technology (weak in some contexts) when its replacement can only be done with such significant changes (eg: a new authentication system or a different database engine) that it would block developers who may not be responsible for the architecture of the application.
- This section ends with "There is a risk if you answered yes to any of those questions."
- Recommended Secure Coding Practices: describing all the ways to mitigate the risk.
- This part can be easily translated by a developer into examples of implementation/source code, if the recommendations are too abstract the developer will not be able to imagine the fix and decide whether to implement it.
- The following parts are mandatory in RSPEC language-specification:
- Sensitive Code Example: same as "Noncompliant code example" for Bug, Vulnerability, and Code Smell rules.
- Compliant Solution: same as for Bug, Vulnerability, and Code Smell rules.
- See: (optional) same as for Bug, Vulnerability, and Code Smell rules.
- Deprecated: (optional) listing replacement rules with links.
Guidelines regarding COBOL, keywords, and code are the same as for other rules.
Messages
Most of the time you can paraphrase the title:
- Start the sentence with "Make sure that"
- Replace "is security-sensitive" with "is safe here"
Examples:
- Make sure creating this cookie without the "secure" flag is safe.
© 2008-2024 SonarSource SA. All rights reserved. SONAR, SONARSOURCE, SONARLINT, SONARQUBE, SONARCLOUD, and CLEAN AS YOU CODE are trademarks of SonarSource SA.